Continuous Algebraic Riccati Equation of 2 States Example
![]() Open access
Open access
Optimal Solution to Matrix Riccati Equation – For Kalman Filter Implementation
Submitted: December 5th, 2011 Published: September 26th, 2012
DOI: 10.5772/46456
From the Edited Volume
MATLAB
Edited by Vasilios N. Katsikis

IntechOpen Downloads
14,407
Total Chapter Downloads on intechopen.com
![]()
Altmetric score
Overall attention for this chapters
*Address all correspondence to:
1. Introduction
Matrix Riccati Equations arise frequently in applied mathematics, science, and engineering problems. These nonlinear matrix equations are particularly significant in optimal control, filtering, and estimation problems. Essentially, solving a Riccati equation is a central issue in optimal control theory. The needs for such equations are common in the analysis and synthesis of Linear Quadratic Gaussian (LQC) control problems. In one form or the other, Riccati Equations play significant roles in optimal control of multivariable and large-scale systems, scattering theory, estimation, and detection processes. In addition, closed forms solution of Riccti Equations are intractable for two reasons namely; one, they are nonlinear and two, are in matrix forms. In the past, a number of unconventional numerical methods were employed for the solutions of time-invariant Riccati Differential Equations (RDEs). Despite their peculiar structure, no unconventional methods suitable for time-varying RDEs have been constructed, except for carefully re-designed conventional linear multistep and Runge-Kutta(RK) methods.
Implicit conventional methods that are preferred to explicit ones for stiff systems are premised on the solutions of nonlinear systems of equations with higher dimensions than the original problems via Runge-Kutta methods. Such procedural techniques do not only pose implementation difficulties but are also very expensive because they require solving robust non-linear matrix equations.
In this Chapter, we shall focus our attention on the numerical solution of Riccati Differential Equations (RDEs) for computer-aided control systems design using the numerical algorithm with an adaptive step of
Advertisement
2. Kalman filter
Theoretically the Kalman Filter is an estimator for the linear-quadratic problem, it is an interesting technique for estimating the instantaneous 'state' of a linear dynamic system perturbed by white -noise measurements that is linearly related to the corrupted white noise state. The resulting estimator is statistically optimal with respect to any quadratic function of the estimation error.
In estimation theory, Kalman introduced stochastic notions that applied to non-stationary time-varying systems, via a recursive solution. C.F. Gauss (1777-1855) first used the Kalman filter, for the least-squares approach in planetary orbit problems. The Kalman filter is the natural extension of the Wiener filter to non-stationary stochastic systems. In contrast, the theory of Kalman has provided optimal solutions for control systems with guaranteed performance. These control analyses were computed by solving formal matrix design equations that generally had unique solutions. By a way of reference, the U.S. space program blossomed with a Kalman filter providing navigational data for the first lunar landing.
Practically, it is one of the celebrated discoveries in the history of statistical estimation theory in the twentieth century. It has enable humankind to do many things, one obvious advantage, is its indispensability as silicon integration in the makeup of electronic systems. It's most dependable application is in the control of complex dynamic systems such as continuous manufacturing processes, aircraft, ships, or spacecraft. To control a dynamic system, you must first know what it is doing. For these applications, it is not always possible or desirable to measure every variable that you want to control, and Kalman filter provides a means of inferring the missing information from indirect (and noisy) measurements. Kalman Filter is also very useful for predicting the likely future course of dynamic systems that people are not likely to control, such as the flow of rivers during flood, the trajectory of celestial bodies, or the prices of traded commodities. Kalman Filter is 'ideally noted for digital computer implementation', arising from a finite representation of the estimated problem-by a finite number of variables. Usually, these variables are assumed to be real numbers-with infinite precision. Some of the problems encountered in its uses, arose from its distinction between 'finite' and 'manageable' problem sizes. These are significant issues on the practical side of Kalman filtering that must be considered in conjunction with the theory. It is also a complete statistical characterization of an estimated problem than an estimator, because it propagates the entire probability distribution of the variables in its task to be estimated. This is a complete characterization of the current state of knowledge of the dynamic system, including influence of all past measurements. These probability distributions are also useful for statistical analysis and predictive design of sensor systems. The applications of Kalman filtering encompass many fields, but its use as a tool, is almost exclusively for two purposes: estimation and performance analysis of estimators. Figure 1 depicts the essential subject for the foundation for Kalman filtering theory.
Despite the indication of Kalman filtering process in the apex of the pyramid, it is an integral part in the foundation of another discipline

Figure 1.
Foundation concept in Kalman filtering.
Kalman filter analyses a dynamic systems' behavior with external and measurement noise. In general, the output
By defining, a continuous –time process and measurement model is as follows;
Where,
E2
From the foregoing,a Kalman filter equation admits the form;
where
The covariance matrix
Advertisement
3. Riccati equation
In mathematics, a Riccati equation is any ordinary differential equation that is quadratic in the unknown function. In other words, it is an equation of the form
E5
where,
More generally, "Riccati equations" refer to matrix equations with analogous quadratic terms both in continuous-time and in discrete-time Linear-Quadratic-Gaussian Control. The steady-state (non-dynamic) versions of these equations are classified as algebraic Riccati equations.
3.1. Riccati differential equation (RDE)
The Riccati differential equation was first studied in the eighteen century as a nonlinear scalar differential equation, and a method was derived for transforming it to a linear matrix form. This same method works when the dependent variable of the original Riccati differential equation is a matrix.
The statistical performance of the Kalman filter estimator can be predicted a priori by solving the Riccati equations for computing the optimal feedback gain of the estimator. Also, the behaviors of their solutions can be shown analytically for the most trivial cases. These equations also provide a means for verifying the proper performance of the actual estimator when it is running.
For the LQG problem, the associated Riccati Differential Equation which provides the covariance
E6
where
E7
The Riccati Differential Equation in (6) can be solved by using a technique, called the Matrix Fraction Decomposition. A matrix product of the sort
A fractional decomposition of the covariance matrix results in a linear differential equation for the numerator and the denominator matrices. The numerator and denominator matrices as functions of time, such that the product
E9
Now let us represent the covariance matrix
and on applying equations ( 9-10) yields
E11
From the Riccati equation in (6) substitution for
E12
E13
Equating (11) and (12) and multiplying through with
E14
E15
Therefore, if we find
E16
E17
then
E18
Such a representation is a Hamiltonian Matrix known as matrix Riccati differential equation.
E19
The initial values of
In the time-invariant case, the Hamiltonian matrix Ψ is also time-invariant. As a consequence, the solution for the numerator
E20
where
E21
The scalar time-invariant Riccati differential matrix equation and its linearized equivalent is
E22
Hence, equation (16) reduces to
E23
with the following initial conditions namely;
Using
E25
E26
Consequently, the covariance follows as;
E27
If the system is
E28
The need to solve Riccati equation is perhaps the greatest single cause of anxiety and agony on the part of people faced with implementing Kalman filter. Because there is no general formula for solving higher order polynomials equations (i.e., beyond quartic), finding closed-form solutions to algebraic Riccati equations by purely algebraic means is very rigorous. Thus, it is necessary to employ numerical solution methods. Numbers do not always provide us as much insight into the characteristics of the solution as formulas do, but readily amenable for most problems of practical significance.
3.2. Numerical example – An expendable launch vehicle (ELV) autopilot
This problem is taken from Aliyu et al, and it is significant for modeling and simulating an ELV autopilot problem in Matlab/Simulink®. It solves the symmetrical RDE:
E29
Where,
E30
E31
and
E32
3.3. Numerical Methods and Problem Solving Environment (PSE), for Ordinary Differential Equations
In the last decade, two distinct directions have emerged in the way Ordinary Differential Equation (ODE) solvers software is utilized. These include Large Scale Scientific Computation and PSE. Most practicing engineers and scientists, as well as engineering and science students use numerical software for problem solving, while only a few very specific research applications require large scale computing.
MATLAB® provides several powerful approaches to integrate sets of initial value, Ordinary Differential Equations. We have carried out an extensive study of the requirements. For the simulation of the autopilot problem, we have used the mathematical development environment Matlab/Simulink®. Matlab/Simulink® was chosen, as it is widely used in the field of numerical mathematics and supports solving initial value ordinary differential equations like the type we have in (27) with easy.
From the humble beginnings of Euler's method, numerical solvers started relatively simple and have evolved into the more complex higher order Taylor methods and into the efficient Runge-Kutta methods. And the search for more efficient and accurate methods has led to the more complicated variable step solvers.
3.3.1. One step solver
For solving an initial value problem
a numerical method is needed. One step solvers are defined by a function
E34
where,
E36
with the initial values
E37
describes the differential quotient of the exact solution
In the following,
E38
where they are continuous and limited.
One step solvers must fulfill
This is equivalent to
E40
If this condition holds for all
holds for all x є [a,b], y є R, f є Fp (a,b). The global discretization error
E42
is the difference between exact solution and the approximated solution. The one step method is denoted as
This means that the order of the global discretization error is equal to the order of the local discretization error. The crucial problem concerning one-step methods is the choice of the step size
3.3.2. Explicit Euler
The most elementary method of solving initial value problems is the explicit Euler. The value of
The explicit Euler calculates the new value
3.3.3. Runge-Kutta method
The Runge-Kutta methods are a special kind of one-step solvers, which evaluate the right side in each step several times. The intermediate results are combined linearly. The general discretization schema for one-step of a Runge-Kutta method is
E46
with corrections
E47
The coefficients are summarized in a tableau, the so-called Butcher-tableau, see figure 2.

Figure 2.
Butcher-tableau.
3.4. Step size control
The Runge-Kutta methods use an equidistant grid, but this is for most applications inefficient. A better solution is to use an adaptive step size control. The grid has to be chosen so that
-
a given accuracy of the numerical solution is reached
-
the needed computational effort is minimized.
As the characteristics of the solution are a priori unknown, a good grid structure cannot be chosen before the numerical integration. Instead, the grid points have to be adapted during the computation of the solution. Trying to apply this to Runge-Kutta methods lead to the following technique:
To create a method of order
This method for
where

Figure 3.
Modified Butcher-tableau for embedded Runge-Kutta-methods.
3.4.1. Error control and variable step size
The main concern with numerical solvers is the error made when they approximate a solution. The second concern is the number of computations that must be performed. Both of these can be addressed by creating solvers that use a variable step size in order to keep the error within a specified tolerance. By using the largest step size allowable while keeping the error within a tolerance, the error made is reduced.
The way to keep the error under control is to determine the error made at each step. A common way to do this is to use two solvers of orders
Since the downside of using two distinct methods is a dramatic increase in computations, another method is typically used. An example of this method is the Rung-Kutta-Fehlberg Algorithm. The Rung-Kutta-Fehlberg combines Rung-Kutta methods of order four and order five into one algorithm. Doing this reduces the number of computations made while returning the same result.
3.4.2. Dormand-Prince method
The
E49
The coefficients from Dormand and Prince can be seen in figure 4.

Figure 4.
Butcher-tableau for Dormand-Prince-method.
For solving an initial value problem like the one we have in (27) Matlab was chosen, as it is widely used in the field of numerical mathematics and supports solving ordinary differential equations. Moreover, it is possible to visualize the simulation results of the autopilot. In our program we used the

Figure 5.
Simulink model for matrix Differential Riccati Equation.
After successfully simulating the above model, it was used to design an Linear Quadratic Gaussian (LQG) autopilot with the following Linear Quadratic Regulator (LQR) Characteristics;
E50
For this autopilot, the Kalman-Bucy filter model was implemented as shown in Fig.6. It should be noted that if for any reason the initial condition
Advertisement
4. Filter performance
The dependent variable in the Riccati differential equation of the Kalman-Bucy filter is the covariance matrix of the
E51
The state error covariance matrix is

Figure 6.
Simulink model for Kalman-Bucy filter with a RDE.
The solution of the matrix Riccati equation was found to provide a quantitative measure of how well the state variables can be estimated in terms of mean-squared estimation errors. Therefore, the matrix Riccati equation from the Kalman filter was soon recognized as a practical model for predicting the performance of sensor systems, and it became the standard model for designing aerospace sensor systems to meet specified performance requirements. More importantly, covariance analysis is crucial in exploring what-if scenarios with new measurement sources.
Note that in (27) we increase estimation uncertainty by adding in process noise and we decrease estimation uncertainty by the amount of information (
For an initial guess for the value of covariance, a very large value could be selected if one is using a very poor sensor for measurement. This makes the filter very conservative. Converse is the case if very good sensors are used for measurement.
The LQG autopilot simulation for tracking a pitch angle of 3 degrees (0.05rads) with the observer as designed in Fig.6 gave the result presented in Fig.7. It is interesting to note that the time response characteristics of the simulated autopilot in Fig. 7 meets all the design specifications of;

Figure 7.
Set-point command tracking of LQG autopilot for a RDE solution to Kalman gain.
The numerical result at
E52
E53
A further investigation was carried out-the single point value of Kalman filter gain given in (48) was used to implement the Kalman filter algorithm as popular represented in most textbooks-as a constant gain. For which, the Kalman-Bucy model in Fig. 8 was developed.

Figure 8.
Simulink Model of Kalman filter model for a constant gain value of Kalman gain.
Hence, the same LQG autopilot was simulated with the Kalman filter based observer as shown in Fig.8. Simulation result for the system is as shown in Fig. 9. It is also interesting to note that all the time response characteristics as earlier mentioned were met. Though, the
The Matlab in-built command function
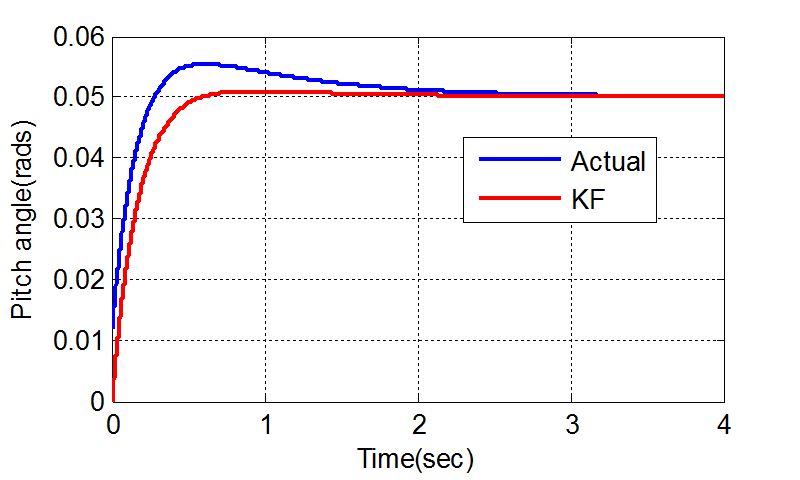
Figure 9.
Set point command tracking of ELV autopilot for a Kalman gain obtained by evaluating covariance matrix to a Riccati Differential Equation at t=1sec.
Advertisement
5. Algebraic Riccati equation
Assume that the Riccati differential equation has an asymptotically stable solution for P(t):
Then the time derivative vanishes
Substituting this into the (6) yields
E56
This is called the Algebraic Riccati Equation. This is a nonlinear matrix equation, and need a numerical solver to obtain a solution for P∞.
Consider a scalar case:
E58
From (52) there exist two solutions; one positive and the other negative, corresponding to the two values for the signum (±). There is no cause for alarm. The solution that agrees with (52) is the non-negative one. The other solution is non-positive. We are only interested in the non-negative solution, because the variance
E59
For the numerical example at hand, the Kalman gain for this problem is easily solved with the following Matlab command
E60
E61
and
E62
Based, on the result in (54), the LQG autopilot was simulated with the Kalman-Bucy filter state observer as modeled in Fig. 8. The result obtained from this was used in designing an LQG controller for the case of an ELV during atmospheric ascent. This seeks to track and control a pitch angle of 3 degrees (0.05rads) and the result is as shown Figure 10. Though, in this case the controller could bring the ELV to a

Figure 10.
Set-point command tracking of LQG autopilot for an Algebraic Riccati Equation's solution to Kalman gain.
Advertisement
6. Comparative analysis
It can be clearly seen from figure 7 that the result of applying Kalman gain in the LQG problem of an ELV is most suitable by solving the associated Riccati Equation in its differential form (RDE). All time response characteristics were met within a second and with a zero
Though one might be tempted to look at the difference in
It is of paramount interest to add here that the plant and observer dynamics for all cases explored in this research gave a dynamic system with stable poles (

Figure 11.
Compared results of the three approaches to the solution of Kalman gain as applied to an autopilot.
Advertisement
7. Conclusion
It can be clearly seen in Figure 6, that the synthesized LQG autopilot, with Kalman gain obtained by solving an Algebraic Riccati Equation (ARE) has 6
It is required that after designing Kalman filter, the accuracy of estimation is also assessed from the covariance matrix. It could be seen that both cases gave a very good estimation (very small covariance). Though, that of ARE gave a much smaller value. This has less significance to our research since we are majorly interested in the time response characteristic of the controlled plant. MATLAB 2010a was used for all the simulations in this paper.
Advertisement
Acknowledgement
The authors will like to specially appreciate the Honourable
References
- 1.
Aliyu Bhar Kisabo. 2011 Expendable Launch Vehicle Flight Control; Design & Simulation With Matlab/Simulink,973-3-84432-729-8 Germany. - 2.
Shampine L. F. Gladwell I. Thompson S. 2003 Solving ODEs with MATLAB,978-0-51107-707-4 USA. - 3.
Robert H. Bishop 2002 The mechatronics Handbook, Second Edition,0-84930-066-5 Raton, London, New York, Washington D.C - 4.
Mohinder S. Grewal Angus P. Anderson 2001 Applications of kalman Filtering; Theory & practice Using Matlab, Second Edition,0-47126-638-8 York, Chichester, Weinhem, Brisban,Sigapore,Toronto - 5.
Aliyu Bhar Kisabo et al 2011 Autopilot Design for a Generic Based Expendable Launch Vehicle, Using Linear Quadratic gaussian (LQG) Control. European Journal of Scientific Research,50 4 February 2011),597 611 0145-0216 X - 6.
Reza Abazari. 2009 Solution of Riccati Type Differential Equations Using Matrix Differential Transform. Journal of Applied Mathematics & Informatics,27 5-6 December 2009),1133 1143
Submitted: December 5th, 2011 Published: September 26th, 2012
© 2012 The Author(s). Licensee IntechOpen. This chapter is distributed under the terms of the Creative Commons Attribution 3.0 License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Source: https://www.intechopen.com/chapters/39345
{kind=link}
Post a Comment for "Continuous Algebraic Riccati Equation of 2 States Example"